19-154 Vol. 3B
PERFORMANCE-MONITORING EVENTS
19.13 PERFORMANCE MONITORING EVENTS FOR 45 NM AND 32 NM
INTEL
®
ATOM
™
PROCESSORS
45 nm and 32 nm processors based on the Intel
®
Atom™ microarchitecture support the architectural performance-
monitoring events listed in Table 19-1 and fixed-function performance events using fixed counter listed in Table
19-22. In addition, they also support the following non-architectural performance-monitoring events listed in Table
19-26.
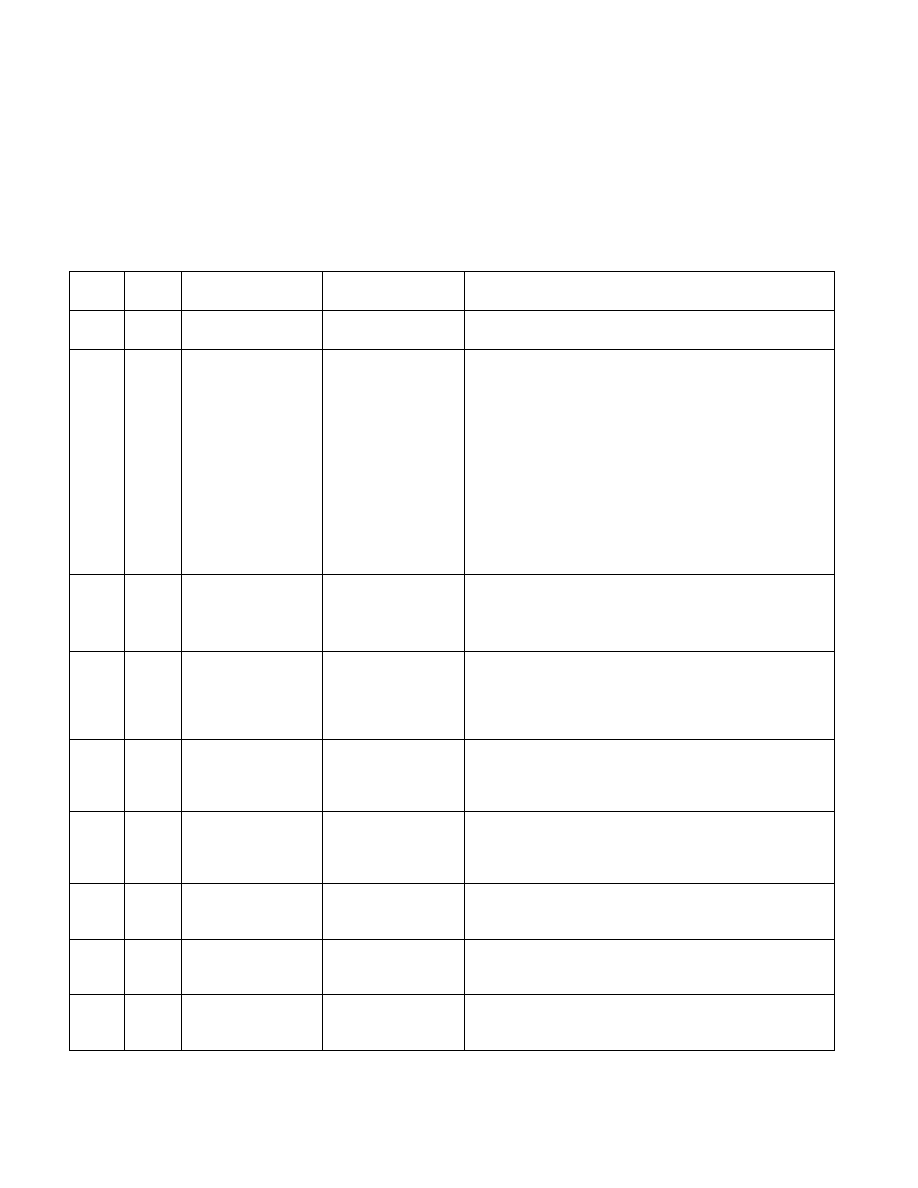
Table 19-26. Non-Architectural Performance Events for 45 nm, 32 nm Intel® Atom™ Processors
Event
Num.
Umask
Value
Event Name
Definition
Description and Comment
02
H
81
H
STORe_FORWARDS.GO
OD
Good store forwards.
This event counts the number of times store data was
forwarded directly to a load.
06
H
00
H
SEGMENT_REG_
LOADS.ANY
Number of segment
register loads.
This event counts the number of segment register load
operations. Instructions that load new values into segment
registers cause a penalty. This event indicates performance
issues in 16-bit code. If this event occurs frequently, it may be
useful to calculate the number of instructions retired per
segment register load. If the resulting calculation is low (on
average a small number of instructions are executed between
segment register loads), then the code’s segment register
usage should be optimized.
As a result of branch misprediction, this event is speculative and
may include segment register loads that do not actually occur.
However, most segment register loads are internally serialized
and such speculative effects are minimized.
07
H
01
H
PREFETCH.PREFETCHT
0
Streaming SIMD
Extensions (SSE)
PrefetchT0
instructions executed.
This event counts the number of times the SSE instruction
prefetchT0 is executed. This instruction prefetches the data to
the L1 data cache and L2 cache.
07
H
06
H
PREFETCH.SW_L2
Streaming SIMD
Extensions (SSE)
PrefetchT1 and
PrefetchT2
instructions executed.
This event counts the number of times the SSE instructions
prefetchT1 and prefetchT2 are executed. These instructions
prefetch the data to the L2 cache.
07
H
08
H
PREFETCH.PREFETCHN
TA
Streaming SIMD
Extensions (SSE)
Prefetch NTA
instructions executed.
This event counts the number of times the SSE instruction
prefetchNTA is executed. This instruction prefetches the data
to the L1 data cache.
08H
07H
DATA_TLB_MISSES.DT
LB_MISS
Memory accesses that
missed the DTLB.
This event counts the number of Data Table Lookaside Buffer
(DTLB) misses. The count includes misses detected as a result
of speculative accesses. Typically a high count for this event
indicates that the code accesses a large number of data pages.
08H
05H
DATA_TLB_MISSES.DT
LB_MISS_LD
DTLB misses due to
load operations.
This event counts the number of Data Table Lookaside Buffer
(DTLB) misses due to load operations. This count includes
misses detected as a result of speculative accesses.
08H
09H
DATA_TLB_MISSES.L0
_DTLB_MISS_LD
L0_DTLB misses due to
load operations.
This event counts the number of L0_DTLB misses due to load
operations. This count includes misses detected as a result of
speculative accesses.
08H
06H
DATA_TLB_MISSES.DT
LB_MISS_ST
DTLB misses due to
store operations.
This event counts the number of Data Table Lookaside Buffer
(DTLB) misses due to store operations. This count includes
misses detected as a result of speculative accesses.