Vol. 3B 18-79
PERFORMANCE MONITORING
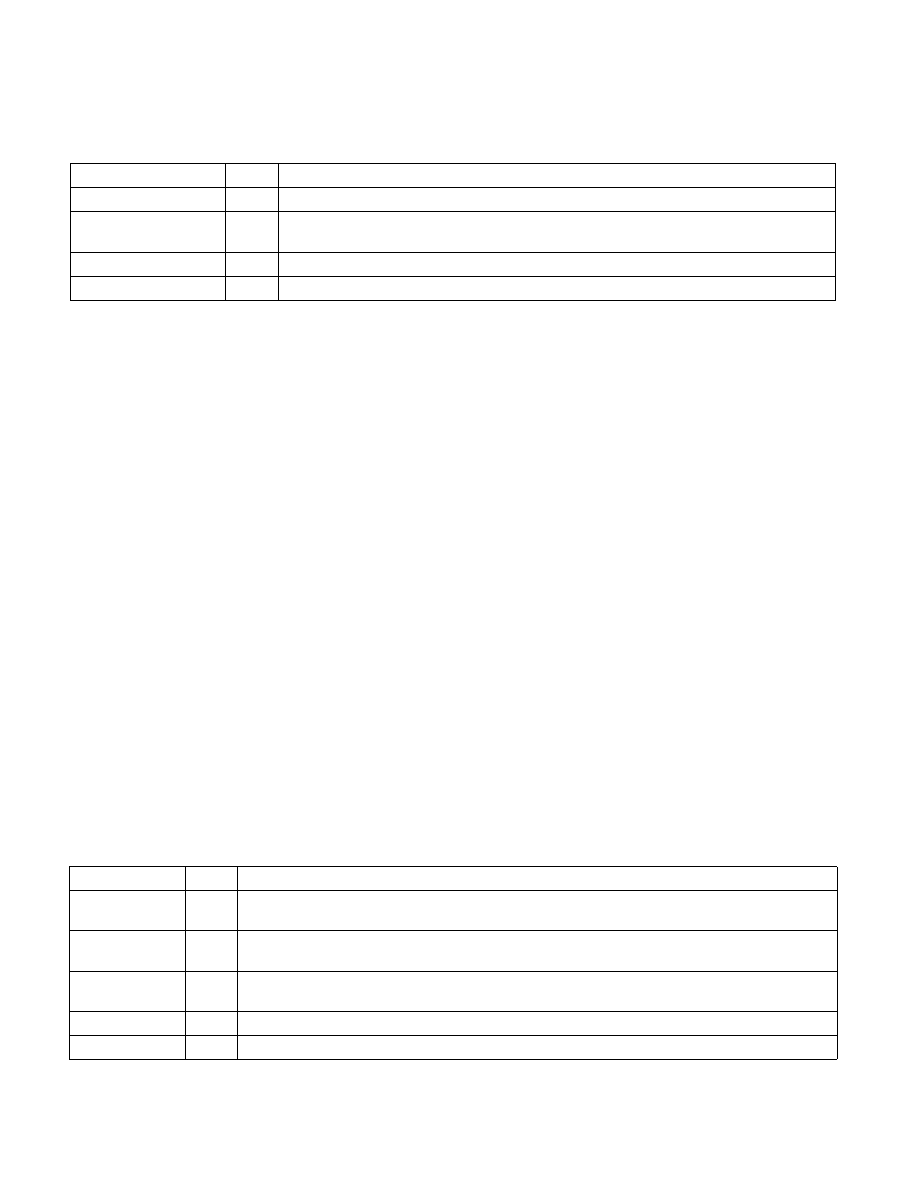
The layout of MSR_PEBS_FRONTEND is given in Table 18-59.
18.13.1.5 FRONTEND_RETIRED
The FRONTEND_RETIRED event is designed to help software developers identify exact instructions that caused
front-end issues. There are some instances in which the event will, by design, the under-counting scenarios include
the following:
•
The event counts only retired (non-speculative) Frontend events, i.e. events from just true program execution
path are counted.
•
The event will count once per cacheline (at most). If a cacheline contains multiple instructions which caused
front-end misses, the count will be only 1 for that line.
•
If the multibyte sequence of an instruction spans across two cachelines and causes a miss it will be recorded
once. If there were additional misses in the second cacheline, they will not be counted separately.
•
If a multi-uop instruction exceeds the allocation width of one cycle, the bubbles associated with these uops will
be counted once per that instruction.
•
If 2 instructions are fused (macro-fusion), and either of them or both cause front-end misses, it will be counted
once for the fused instruction.
•
If a frontend (miss) event occurs outside instruction boundary (e.g. due to processor handling of architectural
event), it may be reported for the next instruction to retire.
18.13.2 Off-core Response Performance Monitoring
The core PMU facility to collect off-core response events are similar to those described in Section 18.9.5. Each
event code for off-core response monitoring requires programming an associated configuration MSR,
MSR_OFFCORE_RSP_x. Software must program MSR_OFFCORE_RSP_x according to:
•
Transaction request type encoding (bits 15:0): see Table 18-60.
•
Supplier information (bits 30:16): see Table 18-61.
•
Snoop response information (bits 37:31): see Table 18-62.
Table 18-59. MSR_PEBS_FRONTEND Layout
Bit Name
Offset Description
EVTSEL
7:0
Encodes the sub-event within FrontEnd_Retired that can use PEBS facility, see Table 18-58
IDQ_Bubble_Length
19:8
Specifies the threshold of continuously elapsed cycles for the specified width of bubbles when
counting IDQ_READ_BUBBLES event
IDQ_Bubble_Width
22:20
Specifies the threshold of simultaneous bubbles when counting IDQ_READ_BUBBLES event
Reserved
63:23
Reserved
Table 18-60. MSR_OFFCORE_RSP_x Request_Type Definition (Skylake microarchitecture)
Bit Name
Offset Description
DMND_DATA_RD
0
(R/W). Counts the number of demand data reads of full and partial cachelines as well as demand data
page table entry cacheline reads. Does not count hw or sw prefetches.
DMND_RFO
1
(R/W). Counts the number of demand reads for ownership (RFO) requests generated by a write to data
cacheline. Does not count L2 RFO prefetches.
DMND_IFETCH
2
(R/W). Counts the number of demand and DCU prefetch instruction cacheline reads. Does not count L2
code read prefetches.
Reserved
6:3
Reserved
PF_L3_DATA_RD
7
(R/W). Counts the number of MLC prefetches into L3.