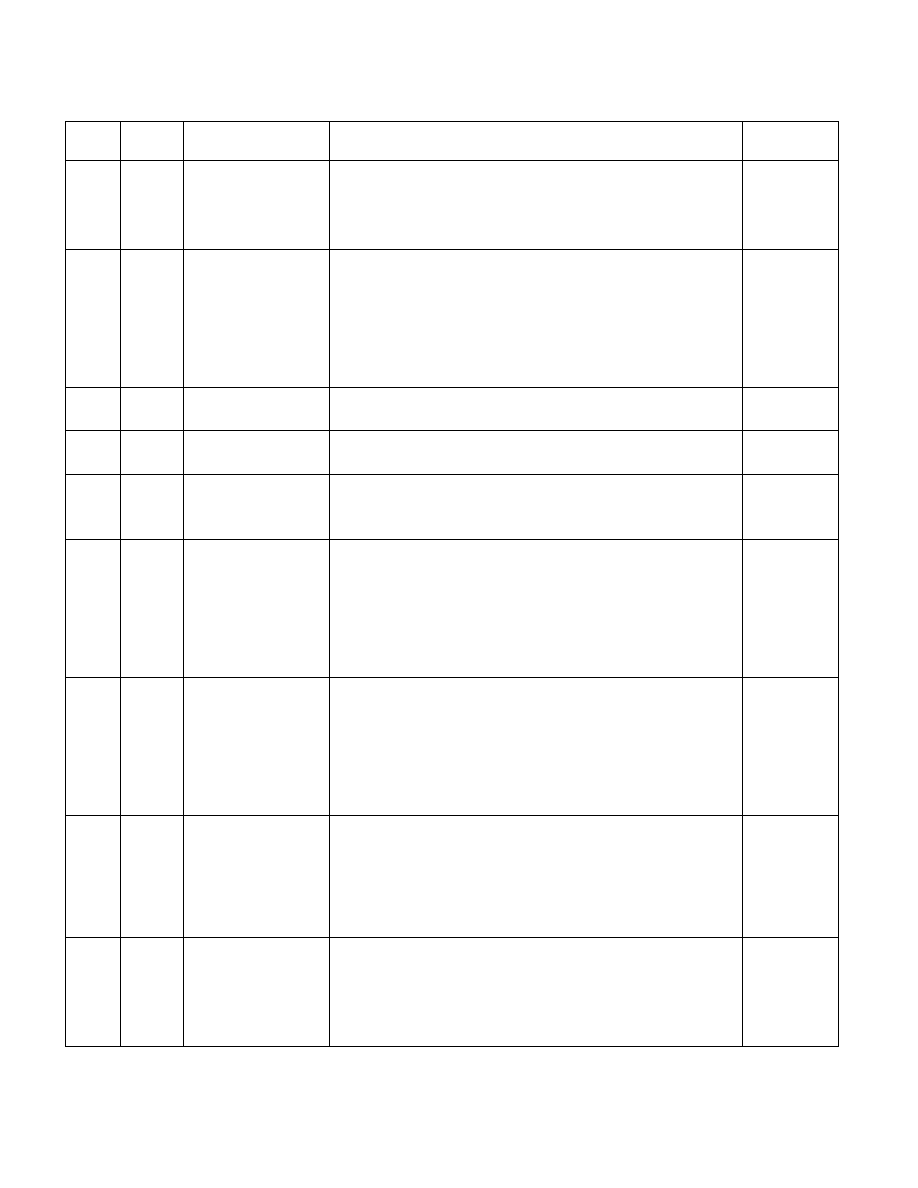
19-144 Vol. 3B
PERFORMANCE-MONITORING EVENTS
30H
00H
L2_REJECT_XQ.ALL
Counts the number of demand and prefetch transactions that the L2
XQ rejects due to a full or near full condition which likely indicates back
pressure from the intra-die interconnect (IDI) fabric. The XQ may reject
transactions from the L2Q (non-cacheable requests), L2 misses and L2
write-back victims.
31H
00H
CORE_REJECT_L2Q.ALL Counts the number of demand and L1 prefetcher requests rejected by
the L2Q due to a full or nearly full condition which likely indicates back
pressure from L2Q. It also counts requests that would have gone
directly to the XQ, but are rejected due to a full or nearly full condition,
indicating back pressure from the IDI link. The L2Q may also reject
transactions from a core to ensure fairness between cores, or to delay
a core's dirty eviction when the address conflicts with incoming
external snoops.
3CH
00H
CPU_CLK_UNHALTED.C
ORE_P
Core cycles when core is not halted. This event uses a programmable
general purpose performance counter.
3CH
01H
CPU_CLK_UNHALTED.R
EF
Reference cycles when core is not halted. This event uses a
programmable general purpose performance counter.
51H
01H
DL1.DIRTY_EVICTION
Counts when a modified (dirty) cache line is evicted from the data L1
cache and needs to be written back to memory. No count will occur if
the evicted line is clean, and hence does not require a writeback.
80H
01H
ICACHE.HIT
Counts requests to the Instruction Cache (ICache) for one or more
bytes in an ICache Line and that cache line is in the Icache (hit). The
event strives to count on a cache line basis, so that multiple accesses
which hit in a single cache line count as one ICACHE.HIT. Specifically, the
event counts when straight line code crosses the cache line boundary,
or when a branch target is to a new line, and that cache line is in the
ICache. This event counts differently than Intel processors based on
the Silvermont microarchitecture.
80H
02H
ICACHE.MISSES
Counts requests to the Instruction Cache (ICache) for one or more
bytes in an ICache Line and that cache line is not in the Icache (miss).
The event strives to count on a cache line basis, so that multiple
accesses which miss in a single cache line count as one ICACHE.MISS.
Specifically, the event counts when straight line code crosses the cache
line boundary, or when a branch target is to a new line, and that cache
line is not in the ICache. This event counts differently than Intel
processors based on the Silvermont microarchitecture.
80H
03H
ICACHE.ACCESSES
Counts requests to the Instruction Cache (ICache) for one or more
bytes in an ICache Line. The event strives to count on a cache line basis,
so that multiple fetches to a single cache line count as one
ICACHE.ACCESS. Specifically, the event counts when accesses from
straight line code crosses the cache line boundary, or when a branch
target is to a new line. This event counts differently than Intel
processors based on the Silvermont microarchitecture.
81H
04H
ITLB.MISS
Counts the number of times the machine was unable to find a
translation in the Instruction Translation Lookaside Buffer (ITLB) for a
linear address of an instruction fetch. It counts when new translations
are filled into the ITLB. The event is speculative in nature, but will not
count translations (page walks) that are begun and not finished, or
translations that are finished but not filled into the ITLB.
Table 19-24. Non-Architectural Performance Events for the Goldmont Microarchitecture (Contd.)
Event
Num.
Umask
Value
Event Name
Description
Comment