19-88 Vol. 3B
PERFORMANCE-MONITORING EVENTS
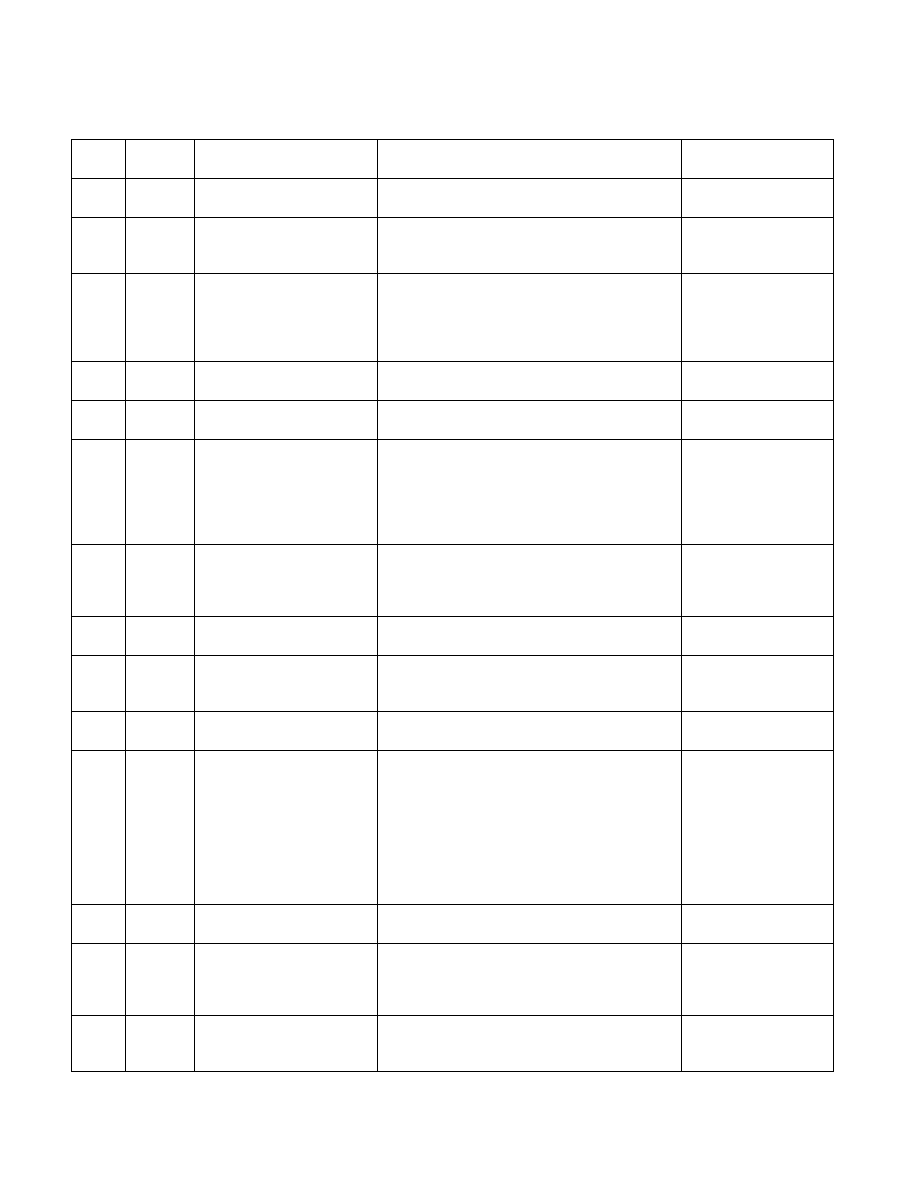
12H
40H
SIMD_INT_128.SHUFFLE_MOV
E
Counts number of 128 bit SIMD integer shuffle and
move operations.
13H
01H
LOAD_DISPATCH.RS
Counts number of loads dispatched from the
Reservation Station that bypass the Memory Order
Buffer.
13H
02H
LOAD_DISPATCH.RS_DELAYED Counts the number of delayed RS dispatches at the
stage latch. If an RS dispatch cannot bypass to LB, it
has another chance to dispatch from the one-cycle
delayed staging latch before it is written into the
LB.
13H
04H
LOAD_DISPATCH.MOB
Counts the number of loads dispatched from the
Reservation Station to the Memory Order Buffer.
13H
07H
LOAD_DISPATCH.ANY
Counts all loads dispatched from the Reservation
Station.
14H
01H
ARITH.CYCLES_DIV_BUSY
Counts the number of cycles the divider is busy
executing divide or square root operations. The
divide can be integer, X87 or Streaming SIMD
Extensions (SSE). The square root operation can be
either X87 or SSE. Set 'edge =1, invert=1, cmask=1'
to count the number of divides.
Count may be incorrect
When SMT is on.
14H
02H
ARITH.MUL
Counts the number of multiply operations executed.
This includes integer as well as floating point
multiply operations but excludes DPPS mul and
MPSAD.
Count may be incorrect
When SMT is on.
17H
01H
INST_QUEUE_WRITES
Counts the number of instructions written into the
instruction queue every cycle.
18H
01H
INST_DECODED.DEC0
Counts number of instructions that require decoder
0 to be decoded. Usually, this means that the
instruction maps to more than 1 uop.
19H
01H
TWO_UOP_INSTS_DECODED
An instruction that generates two uops was
decoded.
1EH
01H
INST_QUEUE_WRITE_CYCLES
This event counts the number of cycles during
which instructions are written to the instruction
queue. Dividing this counter by the number of
instructions written to the instruction queue
(INST_QUEUE_WRITES) yields the average number
of instructions decoded each cycle. If this number is
less than four and the pipe stalls, this indicates that
the decoder is failing to decode enough instructions
per cycle to sustain the 4-wide pipeline.
If SSE* instructions that
are 6 bytes or longer
arrive one after another,
then front end
throughput may limit
execution speed.
20H
01H
LSD_OVERFLOW
Number of loops that cannot stream from the
instruction queue.
24H
01H
L2_RQSTS.LD_HIT
Counts number of loads that hit the L2 cache. L2
loads include both L1D demand misses as well as
L1D prefetches. L2 loads can be rejected for various
reasons. Only non rejected loads are counted.
24H
02H
L2_RQSTS.LD_MISS
Counts the number of loads that miss the L2 cache.
L2 loads include both L1D demand misses as well as
L1D prefetches.
Table 19-19. Non-Architectural Performance Events In the Processor Core for
Processors Based on Intel® Microarchitecture Code Name Westmere (Contd.)
Event
Num.
Umask
Value
Event Mask Mnemonic
Description
Comment