MULPD—Multiply Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, M-U
4-146 Vol. 2B
MULPD—Multiply Packed Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Multiply packed double-precision floating-point values from the first source operand with corresponding values in
the second source operand, and stores the packed double-precision floating-point results in the destination
operand.
EVEX encoded versions: The first source operand (the second operand) is a ZMM/YMM/XMM register. The second
source operand can be a ZMM/YMM/XMM register, a 512/256/128-bit memory location or a 512/256/128-bit vector
broadcasted from a 64-bit memory location. The destination operand is a ZMM/YMM/XMM register conditionally
updated with writemask k1.
VEX.256 encoded version: The first source operand is a YMM register. The second source operand can be a YMM
register or a 256-bit memory location. The destination operand is a YMM register. Bits (MAX_VL-1:256) of the
corresponding destination ZMM register are zeroed.
VEX.128 encoded version: The first source operand is a XMM register. The second source operand can be a XMM
register or a 128-bit memory location. The destination operand is a XMM register. The upper bits (MAX_VL-1:128)
of the destination YMM register destination are zeroed.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit memory location. The desti-
nation is not distinct from the first source XMM register and the upper bits (MAX_VL-1:128) of the corresponding
ZMM register destination are unmodified.
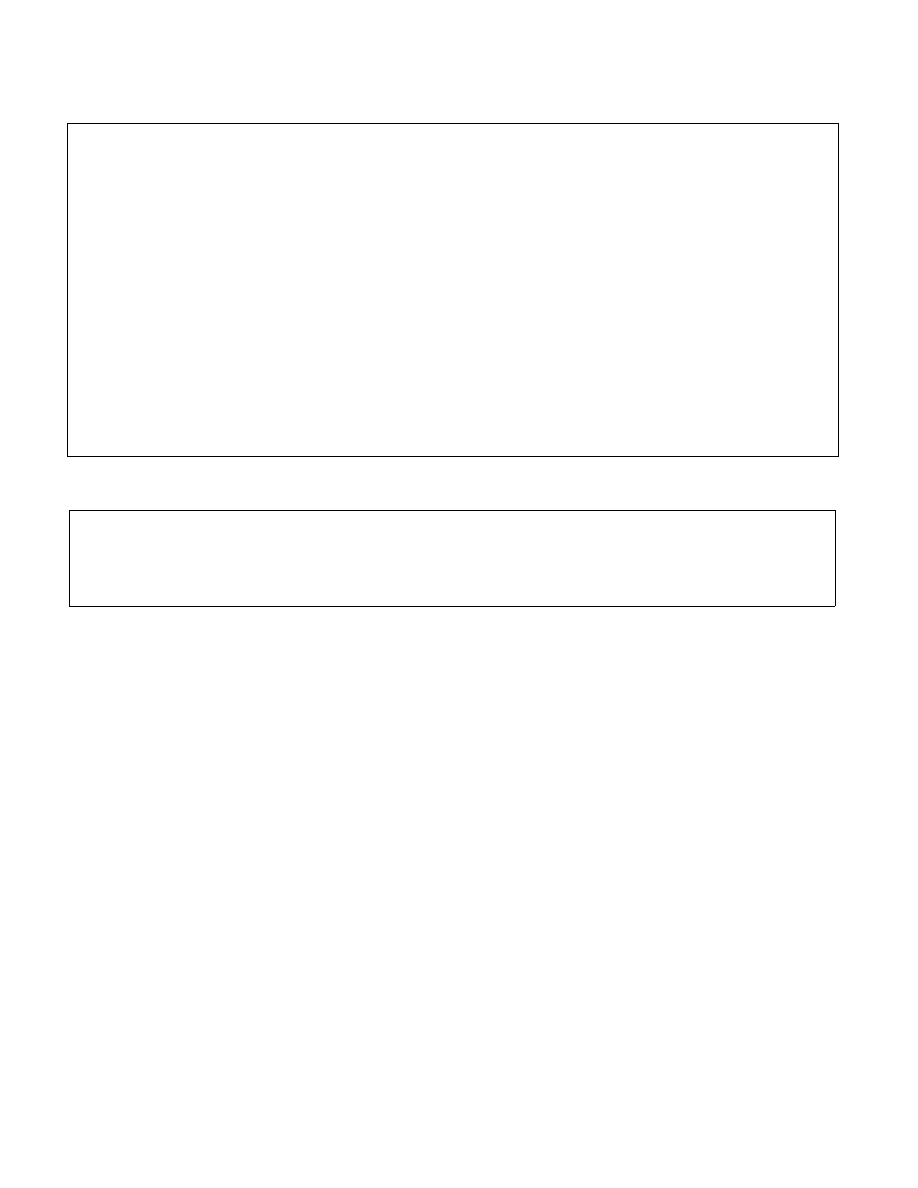
Opcode/
Instruction
Op /
En
64/32
bit Mode
Support
CPUID
Feature
Flag
Description
66 0F 59 /r
RM
V/V
SSE2
Multiply packed double-precision floating-point values
in xmm2/m128 with xmm1 and store result in xmm1.
MULPD xmm1, xmm2/m128
VEX.NDS.128.66.0F.WIG 59 /r
RVM
V/V
AVX
Multiply packed double-precision floating-point values
in xmm3/m128 with xmm2 and store result in xmm1.
VMULPD xmm1,xmm2, xmm3/m128
VEX.NDS.256.66.0F.WIG 59 /r
RVM
V/V
AVX
Multiply packed double-precision floating-point values
in ymm3/m256 with ymm2 and store result in ymm1.
VMULPD ymm1, ymm2, ymm3/m256
EVEX.NDS.128.66.0F.W1 59 /r
FV
V/V
AVX512VL
Multiply packed double-precision floating-point values
from xmm3/m128/m64bcst to xmm2 and store result
in xmm1.
VMULPD xmm1 {k1}{z}, xmm2,
xmm3/m128/m64bcst
AVX512F
EVEX.NDS.256.66.0F.W1 59 /r
FV
V/V
AVX512VL
Multiply packed double-precision floating-point values
from ymm3/m256/m64bcst to ymm2 and store result
in ymm1.
VMULPD ymm1 {k1}{z}, ymm2,
ymm3/m256/m64bcst
AVX512F
EVEX.NDS.512.66.0F.W1 59 /r
FV
V/V
AVX512F
Multiply packed double-precision floating-point values
in zmm3/m512/m64bcst with zmm2 and store result
in zmm1.
VMULPD zmm1 {k1}{z}, zmm2,
zmm3/m512/m64bcst{er}
Op/En
Operand 1
Operand 2
Operand 3
Operand 4
RM
ModRM:reg (r, w)
ModRM:r/m (r)
NA
NA
RVM
ModRM:reg (w)
VEX.vvvv (r)
ModRM:r/m (r)
NA
FV
ModRM:reg (w)
EVEX.vvvv (r)
ModRM:r/m (r)
NA