2-8 Vol. 1
INTEL
®
64 AND IA-32 ARCHITECTURES
To ensure a steady supply of instructions and data for the instruction execution pipeline, the P6 processor microar-
chitecture incorporates two cache levels. The Level 1 cache provides an 8-KByte instruction cache and an 8-KByte
data cache, both closely coupled to the pipeline. The Level 2 cache provides 256-KByte, 512-KByte, or 1-MByte
static RAM that is coupled to the core processor through a full clock-speed 64-bit cache bus.
The centerpiece of the P6 processor microarchitecture is an out-of-order execution mechanism called dynamic
execution. Dynamic execution incorporates three data-processing concepts:
•
Deep branch prediction allows the processor to decode instructions beyond branches to keep the instruction
pipeline full. The P6 processor family implements highly optimized branch prediction algorithms to predict the
direction of the instruction.
•
Dynamic data flow analysis requires real-time analysis of the flow of data through the processor to
determine dependencies and to detect opportunities for out-of-order instruction execution. The out-of-order
execution core can monitor many instructions and execute these instructions in the order that best optimizes
the use of the processor’s multiple execution units, while maintaining the data integrity.
•
Speculative execution refers to the processor’s ability to execute instructions that lie beyond a conditional
branch that has not yet been resolved, and ultimately to commit the results in the order of the original
instruction stream. To make speculative execution possible, the P6 processor microarchitecture decouples the
dispatch and execution of instructions from the commitment of results. The processor’s out-of-order execution
core uses data-flow analysis to execute all available instructions in the instruction pool and store the results in
temporary registers. The retirement unit then linearly searches the instruction pool for completed instructions
that no longer have data dependencies with other instructions or unresolved branch predictions. When
completed instructions are found, the retirement unit commits the results of these instructions to memory
and/or the IA-32 registers (the processor’s eight general-purpose registers and eight x87 FPU data registers)
in the order they were originally issued and retires the instructions from the instruction pool.
2.2.2 Intel
NetBurst
®
Microarchitecture
The Intel NetBurst microarchitecture provides:
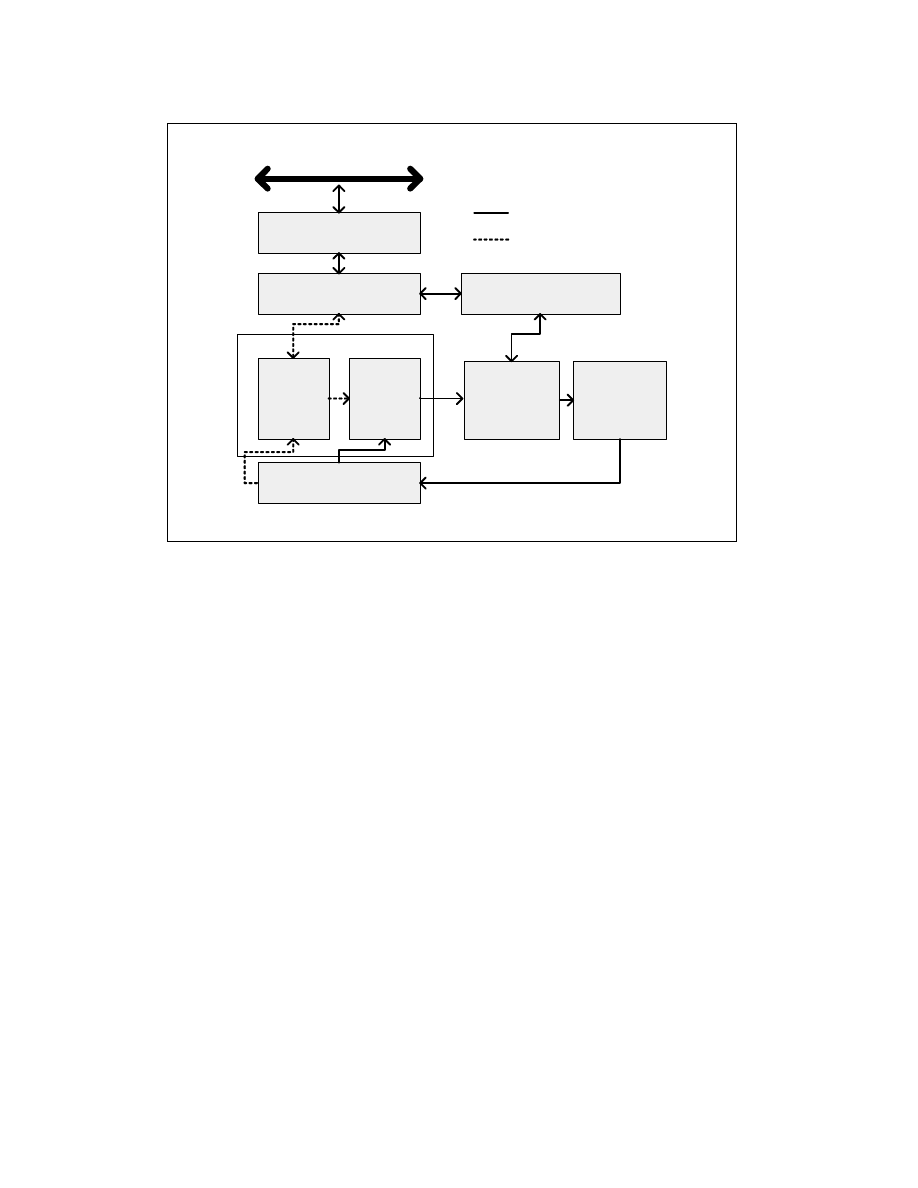
Figure 2-1. The P6 Processor Microarchitecture with Advanced Transfer Cache Enhancement
Bus Unit
2nd Level Cache
On-die, 8-way
1st Level Cache
4-way, low latency
Fetch/
Decode
Execution
Instruction
Cache
Microcode
ROM
Execution
Out-of-Order
Core
Retirement
BTSs/Branch Prediction
System Bus
Branch History Update
Frequently used
Less frequently used
Front End
OM16520