Vol. 1 14-21
PROGRAMMING WITH AVX, FMA AND AVX2
14.5
FUSED-MULTIPLY-ADD (FMA) EXTENSIONS
FMA extensions enhances Intel AVX with high-throughput, arithmetic capabilities covering fused multiply-add,
fused multiply-subtract, fused multiply add/subtract interleave, signed-reversed multiply on fused multiply-add
and multiply-subtract. FMA extensions provide 36 256-bit floating-point instructions to perform computation on
256-bit vectors and additional 128-bit and scalar FMA instructions.
FMA extensions also provide 60 128-bit floating-point instructions to process 128-bit vector and scalar data. The
arithmetic operations cover fused multiply-add, fused multiply-subtract, signed-reversed multiply on fused
multiply-add and multiply-subtract.
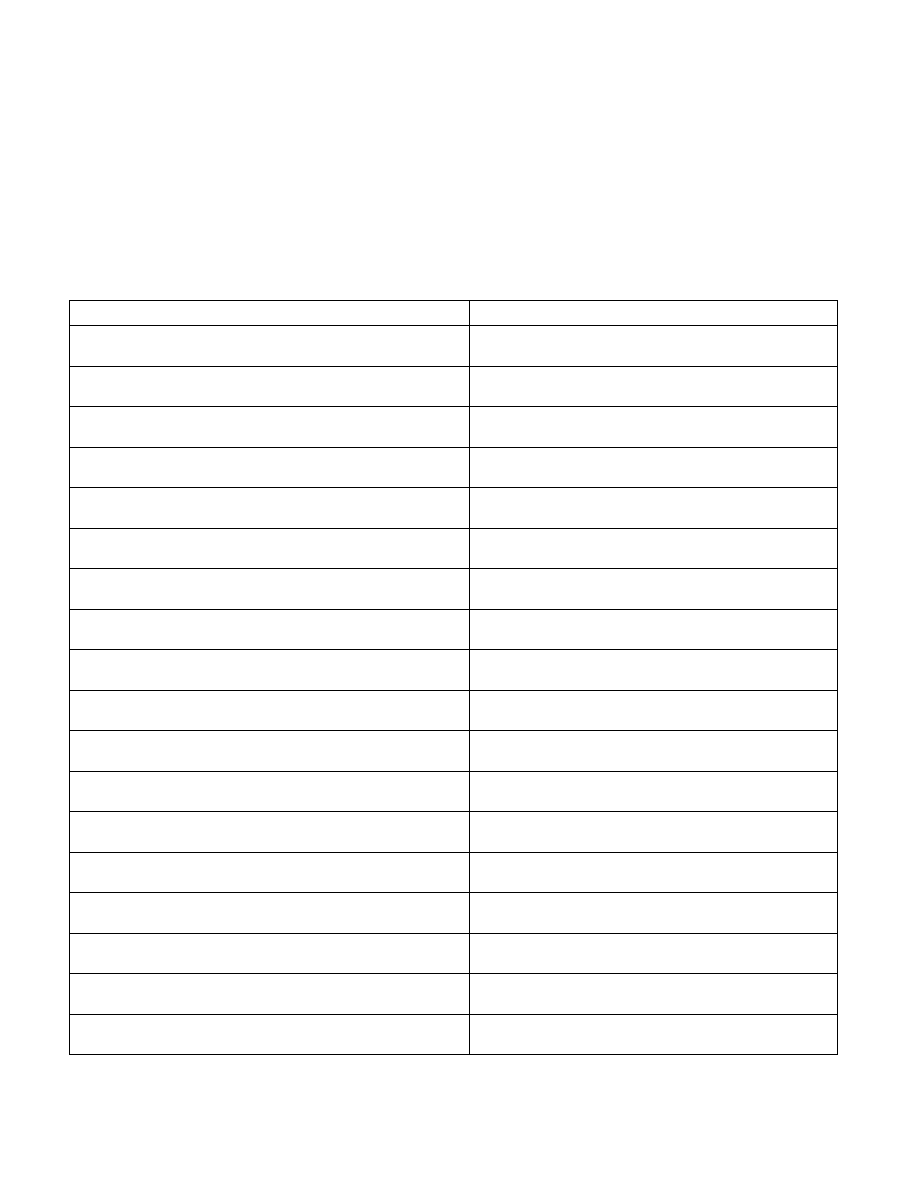
Table 14-15. FMA Instructions
Instruction
Description
VFMADD132PD/VFMADD213PD/VFMADD231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Add of Packed Double-Precision Floating-Point
Values
VFMADD132PS/VFMADD213PS/VFMADD231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Add of Packed Single-Precision Floating-Point
Values
VFMADD132SD/VFMADD213SD/VFMADD231SD
xmm0, xmm1, xmm2/m64
Fused Multiply-Add of Scalar Double-Precision Floating-Point
Values
VFMADD132SS/VFMADD213SS/VFMADD231SS
xmm0, xmm1, xmm2/m32
Fused Multiply-Add of Scalar Single-Precision Floating-Point
Values
VFMADDSUB132PD/VFMADDSUB213PD/VFMADDSUB231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Alternating Add/Subtract of Packed Double-
Precision Floating-Point Values
VFMADDSUB132PS/VFMADDSUB213PS/VFMADDSUB231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Alternating Add/Subtract of Packed Single-Pre-
cision Floating-Point Values
VFMSUBADD132PD/VFMSUBADD213PD/VFMSUBADD231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Alternating Subtract/Add of Packed Double-
Precision Floating-Point Values
VFMSUBADD132PS/VFMSUBADD213PS/VFMSUBADD231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Alternating Subtract/Add of Packed Single-Pre-
cision Floating-Point Values
VFMSUB132PD/VFMSUB213PD/VFMSUB231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Subtract of Packed Double-Precision Floating-
Point Values
VFMSUB132PS/VFMSUB213PS/VFMSUB231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Multiply-Subtract of Packed Single-Precision Floating-
Point Values
VFMSUB132SD/VFMSUB213SD/VFMSUB231SD
xmm0, xmm1, xmm2/m64
Fused Multiply-Subtract of Scalar Double-Precision Floating-
Point Values
VFMSUB132SS/VFMSUB213SS/VFMSUB231SS
xmm0, xmm1, xmm2/m32
Fused Multiply-Subtract of Scalar Single-Precision Floating-
Point Values
VFNMADD132PD/VFNMADD213PD/VFNMADD231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Negative Multiply-Add of Packed Double-Precision Float-
ing-Point Values
VFNMADD132PS/VFNMADD213PS/VFNMADD231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Negative Multiply-Add of Packed Single-Precision Float-
ing-Point Values
VFNMADD132SD/VFNMADD213SD/VFNMADD231SD
xmm0, xmm1, xmm2/m64
Fused Negative Multiply-Add of Scalar Double-Precision Float-
ing-Point Values
VFNMADD132SS/VFNMADD213SS/VFNMADD231SS
xmm0, xmm1, xmm2/m32
Fused Negative Multiply-Add of Scalar Single-Precision Float-
ing-Point Values
VFNMSUB132PD/VFNMSUB213PD/VFNMSUB231PD
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Negative Multiply-Subtract of Packed Double-Precision
Floating-Point Values
VFNMSUB132PS/VFNMSUB213PS/VFNMSUB231PS
xmm0, xmm1, xmm2/m128; ymm0, ymm1, ymm2/m256
Fused Negative Multiply-Subtract of Packed Single-Precision
Floating-Point Values